
Video Retrieval using multi-modal queries (images and text)
Keys words
BLIP, Explainability of Attention Mechanism, Hard-Negative/Filtering Sampling
Objective
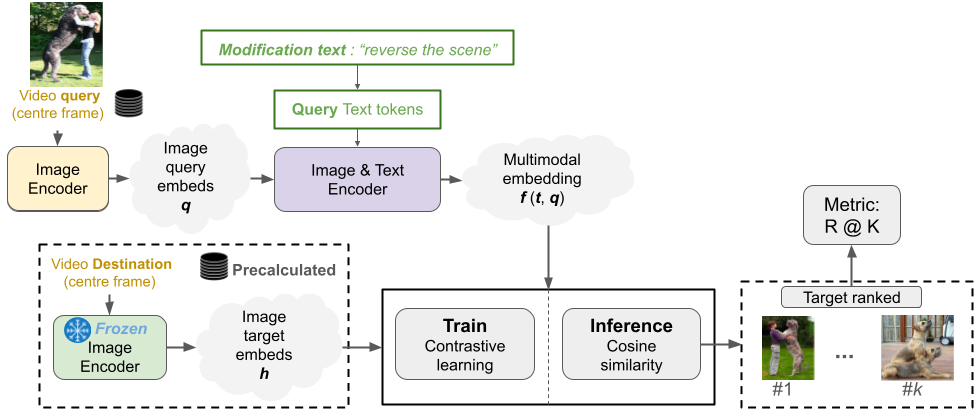
The paper CoVR: Learning Composed Video Retrieval from Web Video Captions introduces for the first time the Composed Video Retrieval (CoVR) task, an advance ment of Composed Image Retrieval (CoIR), integrating text and video queries to enhance video database retrieval. Overcoming the limitations of traditional CoIR methods, which rely on costly manual dataset annotations, the authors developed an automatic dataset creation process and also released states of the art models for CoIR and CoVR. Our aim is to provide a comprehensive analysis of the solutions proposed in the paper, in particular by reproducing their experiments. We also propose to go further by studying explainability using attention mechanisms to understand model predictions. We study the sampling process with three new approaches, and innovate by replacing the original BLIP architecture with the more advanced BLIP-2. As a result, we have obtained a slight improvement compared with the original methods

Links


