
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
portfolio
University research projects
Drive with reports and posters: 
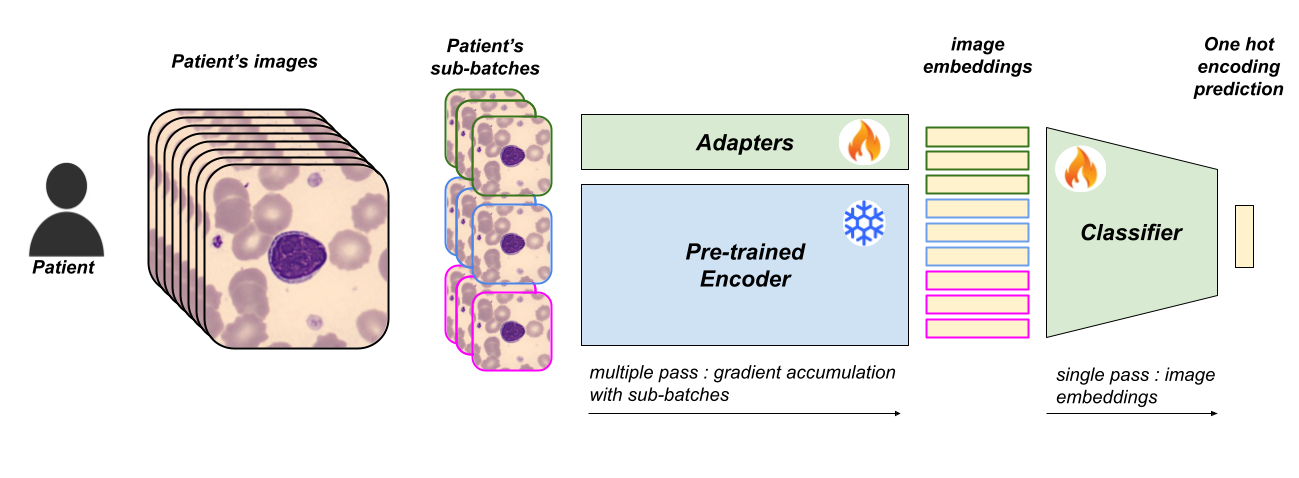
Multiple Instance Learning with multi-modal medical imaging
Keys words
Self-Supervised Learning (MAE, DiNOv2), Cross Attention, Multi-modality, Medical imaging, fitunning (LoRA, Prompt tunning, adapt former), Vision Transformer
Objective
The study focuses on lymphocytosis, an increase in lymphocytes (a type of white blood cell) in the bloodstream. This condition can indicate the body’s immune response to pathogens or be linked to chronic illnesses like blood cancers. Diagnosis involves microscopic examination and clinical tests. To address the reproducibility issue in diagnosis, the study uses Multi-Instance Learning, leveraging Vision Transformers’ ability to capture long-distance relationships between medical images of a patient. They incorporate clinical data to create an efficient, trainable model with low computational resources through distillation and finetuning methods.
Links



![]()
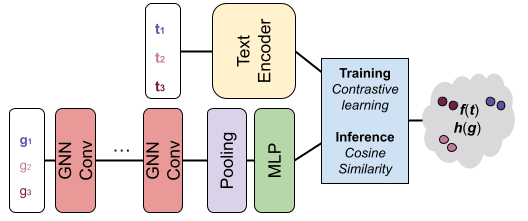
Molecule Retrieval with Natural Language
Keys words
Graph ML, LLM, Contrastive Learning, Multi-Modal
Objective
The aim of the project, as described in the document, is to address the advanced task of retrieving molecules using natural language descriptions as queries, introduced by the paper Text2Mol: Cross-Modal Molecule Retrieval with Natural Language Queries. This challenge involves developing a method to match textual data with molecular structures from a large database effectively.
 Kaggle : ranked 1/52 (122 participants)
Kaggle : ranked 1/52 (122 participants)

Links
Semi/Self-Supervised, Few-shot, novelty instance segmentation
Keys words
Self-supervised (MAE, SAM, DiNOv2, Grounding DiNO), Semi Supervised, few shot, instance segmentation, medical imaging
Objective
This data challenge aims to create a highly accurate model for automatically segmenting anatomical structures and tumors in high-resolution 3D CT scan images of the human body. What makes this challenge unique is that the model does not need prior knowledge of the specific organs or tumors present, and the labeled data does not fully cover all possible anatomical structures. This requires the model to generalize based on shape recognition rather than semantic understanding. Moreover, the challenge is compounded by partially labeled datasets and a pool of unlabeled data for unsupervised training, making it a complex task that combines off-topic learning, few-shot learning, and semi-supervised learning. We tested differents methods with for instance self-supervised for MaskRCNN (DiNOv2, MAE, SAM), semi-supervised with pseudo labelling.
Kaggle : ranked 2/14 (22 participants)

Links
Generative adversarial Model
Keys words
Generative Model (VAE), Adversarial black/white box attack, probabilistic graphical models
Objective
The article Are Generative Classifiers More Robust to Adversarial Attacks? investigates the robustness of deep neural network classifiers against adversarial attacks. The focus is on the comparison between generative classifiers, which model the conditional distribution of labels given inputs, and discriminative classifiers. The authors propose the deep Bayes classifier, which is an improvement over the classical naive Bayes, using conditional deep generative models. We re-implemented the 7 different models from scratch for the MNIST, FashionMNIST and SVHN datasets. We then implemented a white box attack $l_{\infty}$ and a black box attack zoo. We then tested the generative models versus the discriminative models.


Links

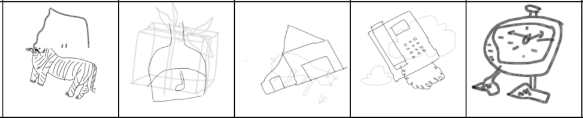
Sketch classification
Keys words
Vision Transformer, Finethunning, Data Augmentation
Objective
The aim of this work is to develop a model capable of classifying the images of the dataset classifysketch with the best accuracy. It is made up of 250 classes of sketches. We will begin by examining the dataset, then discuss the model selection, data augmentation and model tuning that enabled me to achieve 84.7% accuracy on the test dataset using re- sults from [1] and [2] and a new data augmentation
Kaggle : ranked 4/59
Links
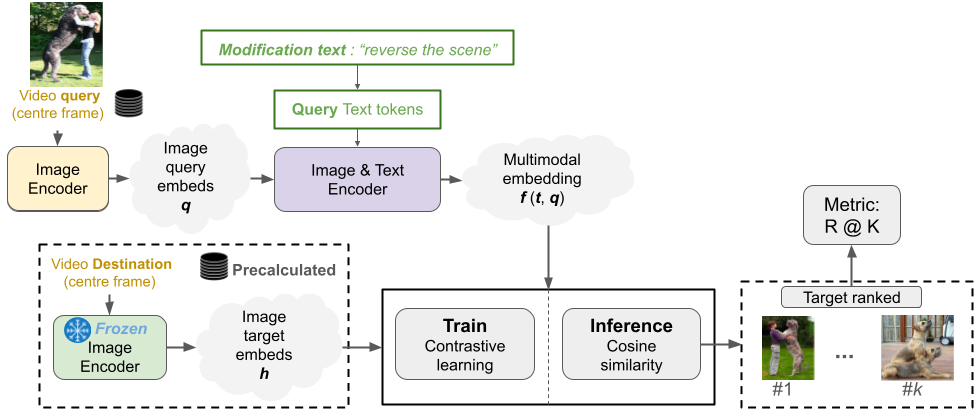
Video Retrieval using multi-modal queries (images and text)
Keys words
BLIP, Explainability of Attention Mechanism, Hard-Negative/Filtering Sampling
Objective
The paper CoVR: Learning Composed Video Retrieval from Web Video Captions introduces for the first time the Composed Video Retrieval (CoVR) task, an advance ment of Composed Image Retrieval (CoIR), integrating text and video queries to enhance video database retrieval. Overcoming the limitations of traditional CoIR methods, which rely on costly manual dataset annotations, the authors developed an automatic dataset creation process and also released states of the art models for CoIR and CoVR. Our aim is to provide a comprehensive analysis of the solutions proposed in the paper, in particular by reproducing their experiments. We also propose to go further by studying explainability using attention mechanisms to understand model predictions. We study the sampling process with three new approaches, and innovate by replacing the original BLIP architecture with the more advanced BLIP-2. As a result, we have obtained a slight improvement compared with the original methods

Links
New loss implementation in Pytorch : Soft-DTW
Keys words
Time Series, DTW, Pytorch
Objective
We re-implemented a differentiable version of Dynamic Time Warping (DTW) named Soft DTW, which allow robust comaprison to shift, length etc. and thereby expanding the utility of DTW in machine learning. Our work contributes to the current discourse on open-source because we have proposed an optimised losses compatible with PyTorch GPU with our own backward.

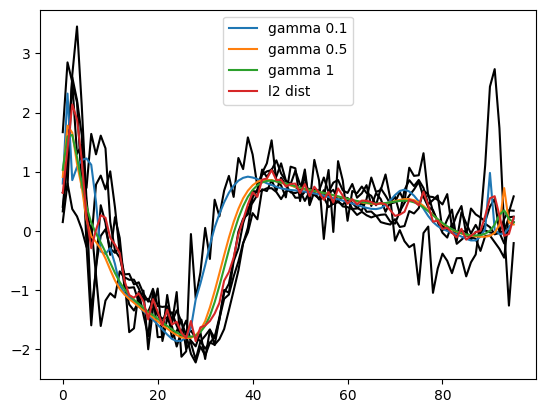
Links
Wasserstein Soft Graph Alignment
Keys words
Optimal transport, Graph alignment
Objective
The aim was to study the paper Wasserstein-based Graph Alignment which studied the alignment of graphs of different sizes in a soft way using optimal transport methods. I re-implemented the paper from scratch as the code was not available.
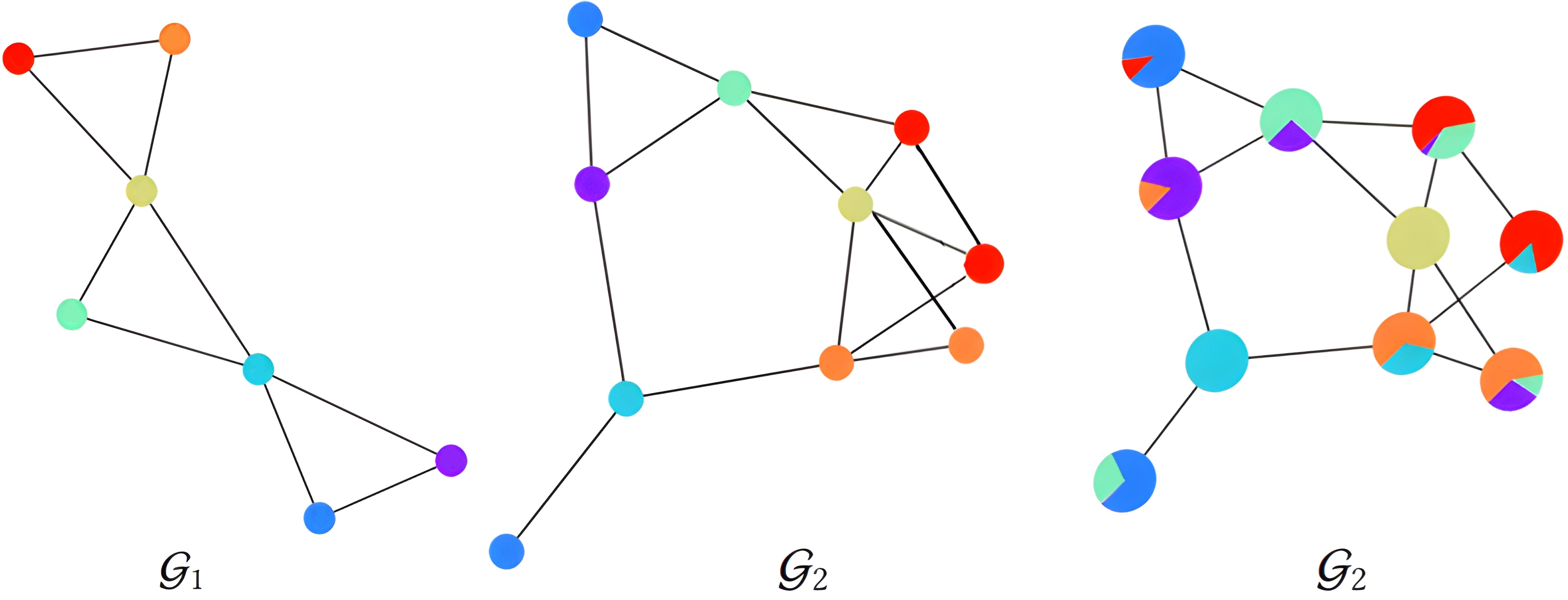
Links
Reinforcement Learning in sparse reward environment : mountain car
Keys words
Reinforcement Learning
Objective
The aim was to explore an example of leanrning reinforcement with sparse reward by comparing model-based versus model-free using the mountain car environment as an application.
Links
Other projects
- Cybersecurity
Length extension attack
Klein attack implementation - Optimal Search
Task scheduling problem with a single machine
Kidney exchange program
Shortest path under resource constraints
Personal Projects
- Create a website in html/css from scratch
- Phone Game cloning
- Web-Scraping / Creation of bots for Instagram
publications
Curia: A Multi-Modal Foundation Model for Radiology
Published in arxiv, 2025
This paper introduce Curia a state-of-the-art medical methods on a newly curated 19-task benchmark (86.7% vs 79.2% for BiomedCLIP and 82.2% for MedImageInsight).
Recommended citation: https://arxiv.org/pdf/2509.06830
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.